“Reading the Mind in the Eyes Test”: Translated and Korean Versions
Article information

Abstract
Objective
The Reading the Mind in the Eyes Test (RMET) was developed by using Caucasian eyes, which may not be appropriate to be used in Korean. The aims of the present study were 1) to develop a Korean version of the RMET (K-RMET) by using Korean eye stimuli and 2) to examine the psychometric properties of the Korean-translated version of the RMET and the K-RMET.
Methods
Thirty-six photographs of Korean eyes were selected. A total of 196 (101 females) healthy subjects were asked to take the Korean-translated version of the RMET and K-RMET. To assess internal consistency reliability, Cronbach’s alpha coefficients were computed, and test–retest reliability was assessed by the intraclass correlation coefficient (ICC) and Bland-Altman plots. Confirmatory factor analysis (CFA) and item analysis were also conducted.
Results
Internal consistency, measured by Cronbach’s alpha, was 0.542 for the Korean-translated version of the RMET, and 0.540 for the K-RMET. Test–retest reliability (n=25), measured by the ICC, was 0.787 for the Korean-translated version of the RMET, and 0.758 for the K-RMET. In CFA, the assumed single and 3-factor model fit indices were not good in the both types of RMETs. There was difficulty in discrimination in nine items of the Korean-translated version of the RMET and 10 items of the K-RMET.
Conclusion
The psychometric properties of both the Korean-translated version of the RMET and the K-RMET are acceptable. Both tests are applicable to the clinical population, as well as the general population in Korea.
INTRODUCTION
Humans can guess other people’s intentions, beliefs, and emotions through verbal and non-verbal information processing even if they do not have direct experience. These processes are referred to as theory of mind (ToM), defined as the ability to understand and attribute to the mental states of others [1,2], which is considered a crucial component of social interaction [3]. Possessing high levels of ToM is advantageous for achieving one’s goal by grasping the other person’s intentions and adequately responding in social interactions [4]. Conversely, ToM deficit was strongly associated with social dysfunction in the clinical population [5-8].
The “Reading the Mind in the Eyes” test (RMET) was developed to provide enriched information about ToM deficit. The initial version of the RMET was published in 1997 [9], while Baron-Cohen and colleagues revised it in 2001 [10]. The revised version consisted of 36 photographs and presented stimuli around the eyes. Participants were asked to choose which of the four options (i.e., one target word and three foils) described the intentions and emotions of the person in the photographs. Since some of the options had similar emotional valence (i.e., positive, negative, or neutral), participants were required to carefully examine each word and photograph and distinguish subtle differences among words for selecting a target word.
The eye stimuli is similar to the Facial Action Coding System (FACS) [11] in that it uses facial expression stimuli. However, the RMET differs in that participants only look at the eyes of the person in the picture and infer that person’s relatively complex mental states [10]. More specifically, participants should know the semantics of the option words and map these terms around that person’s eyes. At the unconscious and automatic level, participants should match these eye stimuli with the representation stored in their memory and determine which word is the closest to their eye expressions. For this reason, the RMET is regarded as a test that measures advanced ToM rather than facial emotion recognition. Thus, the RMET has been translated into different languages and extensively used to measure ToM in various clinical populations [12-19], typical children, and adult populations [20-23].
The original version of the RMET was initially designed to measure ToM in Caucasian populations; thus, the pictures were initially extracted from Caucasian photographs. If the same eye stimuli are conducted for non-Caucasians, differences in race and ethnicity can affect the test performance in various ethnic groups. For example, in a study comparing RMET scores by country [24], the average score of Ethiopian medical students was below 22, which was lower than those of Western students who averaged 25–28 points. In comparison, there are studies [25,26] comparing different versions of RMET using pictures of their respective ethnic groups that show a different result. For example, Caucasian American and Japanese students responded more accurately to a set of eye stimuli that matched their own ethnic group [25], and a partial in-group advantage was also found in Antillean Dutch, Moroccan Dutch, and Dutch samples [26]. Since RMET infers another person’s mental state by using limited information about the eyes and surroundings without other contextual information, presenting Caucasian stimuli to East Asians such as Koreans may lead to more difficulty on the part of the participant.
Given these findings, when conducting RMET research on the Korean population, it is expected that ecological validity can be improved if Korean pictures were used as well. Thus, the aims of the present study were 1) to develop the Korean RMET (K-RMET) by using Korean eye stimuli based on the development process of the original study [10], and 2) to examine the psychometric properties, such as internal consistency, test–retest reliability, confirmatory factor analysis (CFA), distribution of responses and item analysis of the K-RMET and the original RMET, as translated into Korean, with the Korean population.
METHODS
Participants
A total of 196 Korean healthy late adolescents and early adults (101 female, 95 male) were recruited through online job advertisements. Their mean age was 23.02 (SD=2.61), while years of education was 14.41 (SD=1.40). Based on the Mini International Neuropsychiatric Interview (MINI) participants with past or current psychiatric illnesses were excluded. In order to perform the test–retest reliability, some of the participants (n=25) were asked to retake the test. The first test took place during May to July 2018; the retest was conducted from April to October 2019 (test–retest interval: mean=13.96, SD= 1.70; range=11–17 months). All participants provided their written informed consent, and the study was approved by the Institutional Review Board of the Severance Hospital (IRB No: 4-2014-0744).
Measures
For the translation of optional words and a glossary of mental state terms in RMET, a researcher (HJH) with a master’s degree in social psychology, who is fluent in English and Korean, initially translated the RMET to Korean. Thereafter, three experts (psychiatrists ASK and BM and clinical psychologist KSJ) reviewed each word repeatedly until they reached a unanimous agreement regarding the translation.
In the original study, the authors collected photos of actors and actresses from the magazine, and in each photograph, only around the eyes (from just above the eyebrows to the bridge of the nose) were cut to the same size and used as the stimuli of the RMET. To develop the K-RMET, 146 Korean pictures that were judged to be consistent with the eye stimuli of the original study, age (young, middle, elder), gender, pupil orientation, and facial expressions near the eyes were initially selected from the web search engines. Thereafter, two experts (ASK and PJY), who developed the Korean facial expressions of emotion (KOFEE) [27], reviewed the candidate photographs and 41 photos were selected for the pilot test. The pilot test was conducted on another 25 participants (15 female, 10 male). The two measures of accuracy were 75% for the Korean-translated version of the RMET and 71% for the K-RMET. The accuracy of both tests was comparable to those of previous studies (accuracy range=68–78%) [10,28-30].
After the pilot test, 36 items were finally selected for measurement (for details, Supplementary Table 1 in the online-only Data Supplement, for the use of K-RMET, request to the authors). Each subject was asked to respond to the RMETs in an isolated space, and the photos were presented at a resolution of 425×170 pixels on a 17-inch screen using Inquisit 3.0 (Millisecond Software LLC, Seattle, WA, USA). Participants were asked to look at each set of eyes and choose from four options (1 target, 3 foils) that would best describes what the person in the picture is thinking or feeling. One practice item was provided to help participants become familiar with the assignment, and there was no time limit. The target word was scored as 1 point, and the foil was scored as 0; the total score ranged from 0 to 36 points. As with the original paper, in order to minimize the impact of individual vocabulary on the test, a glossary of mental state terms was provided to each participant during all measurement periods, to be consulted at any time during the test. The retest was conducted in the same way as the first test procedure.
Statistical analysis
Data were analyzed using the Statistical Package for the Social Sciences (SPSS), version 25 for Windows (IBM Corporation, Armonk, NY, USA). To perform test–retest reliability, Intraclass correlation coefficients (ICC) with 95% confidence intervals were calculated based on the criteria proposed by Koo and Li [31], which use a mean-rating (κ=2), absolute-agreement, 2-way random-effects model (ICC estimates: Excellent: 0.9–1; Good: 0.75–0.9; Moderate: 0.5–0.75; Poor: 0–0.5) [31]. To obtain additional agreement, the Bland-Altman approach was employed [32,33]. The Bland-Altman plot was calculated and visualized using blandr [34] in RStudio for Windows version 1.2.1335 (RStudio: Integrated Development for R., RStudio, Inc., Boston, MA, USA). In order to examine the factor structure of the measured data, CFA was performed on the single factor model and the three factor model proposed by Harkness et al. [35], based on established criteria [chi-square (CMIN)/df ratio (CMIN/df)<2 [36], root mean square error of approximation (RMSEA)≤0.06, standardized root mean squared residual (SRMR)≤0.08, comparative fit index (CFI)≥0.95, Tucker-Lewis index (TLI)≥0.95 [37]] using AMOS 25 (IBM Corp., Armonk, NY, USA). All tests were two-tailed and conducted at 5% level of statistical significance.
RESULTS
Task performances
Figure 1 showed the distribution of the total scores of the Korean-translated version of the RMET and K-RMET. The mean scores were 25.65 (SD=3.41) and 26.72 (SD=3.38) for the Korean-translated version of the RMET and K-RMET, respectively. There was no gender difference (mean male=25.46; SD=3.61; mean female=25.82; SD=3.21) in the Korean-translated version of the RMET scores [t(194)=0.74; p=0.463], whereas female subjects (mean=27.24; SD=3.09) had significantly higher scores than male subjects (mean=26.17; SD=3.60) in the K-RMET scores [t(194)=2.24; p=0.027].

The distribution of the total scores for the Korean-translated version of the RMET (top) and the K-RMET (bottom). RMET: The Reading the Mind in the Eyes Test.
Reliability analysis
Internal consistency
Cronbach’s alpha was 0.542 for the Korean-translated version of the RMET and 0.540 for the K-RMET. Additionally, Cronbach’s alpha was not found to be improved by excluding any item to improve alpha value in both the Korean-translated version of the RMET and the K-RMET.
Test-retest reliability
Some of the participants (n=25) were asked to retake the test. In the Korean-translated version of the RMET, the mean score for the test was 26.24 (SD=3.49) and 26.68 (SD=3.57) for the retest. In the K-RMET, the mean score for the test was 26.12 (SD=3.57) and 27.16 (SD=3.69) for the retest. Using two related sample Wilcoxon Signed Ranks tests, there were no significant differences in both the Korean-translated version of the RMET (Z=-0.60, p=0.548) and the K-RMET (Z=-1.87, p=0.062) scores. The ICCs were 0.787 with a 95% CI (0.519, 0.906) for the Korean-translated version of the RMET, and 0.758 with a 95% CI (0.462, 0.892) for the K-RMET. To visualize additional agreement between the test and retest, the Bland-Altman plots were reported in Figure 2. In the Korean-translated version of the RMET, the mean difference (test–retest) was -0.44 with 95% CI ranging from -1.67 to 0.79. The upper limit of agreement was 5.39 with 95% CI ranging from 3.26 to 7.51. The lower limit of agreement was -6.27 with 95% CI ranging from -8.39 to -4.14. In the K-RMET, the mean difference was -1.04 with 95% CI ranging from -2.34 to 0.26. The upper limit of agreement was 5.12 with 95% CI ranging from 2.87 to 7.37. The lower limit of agreement was -7.20 with 95% CI ranging from -9.45 to -4.95.
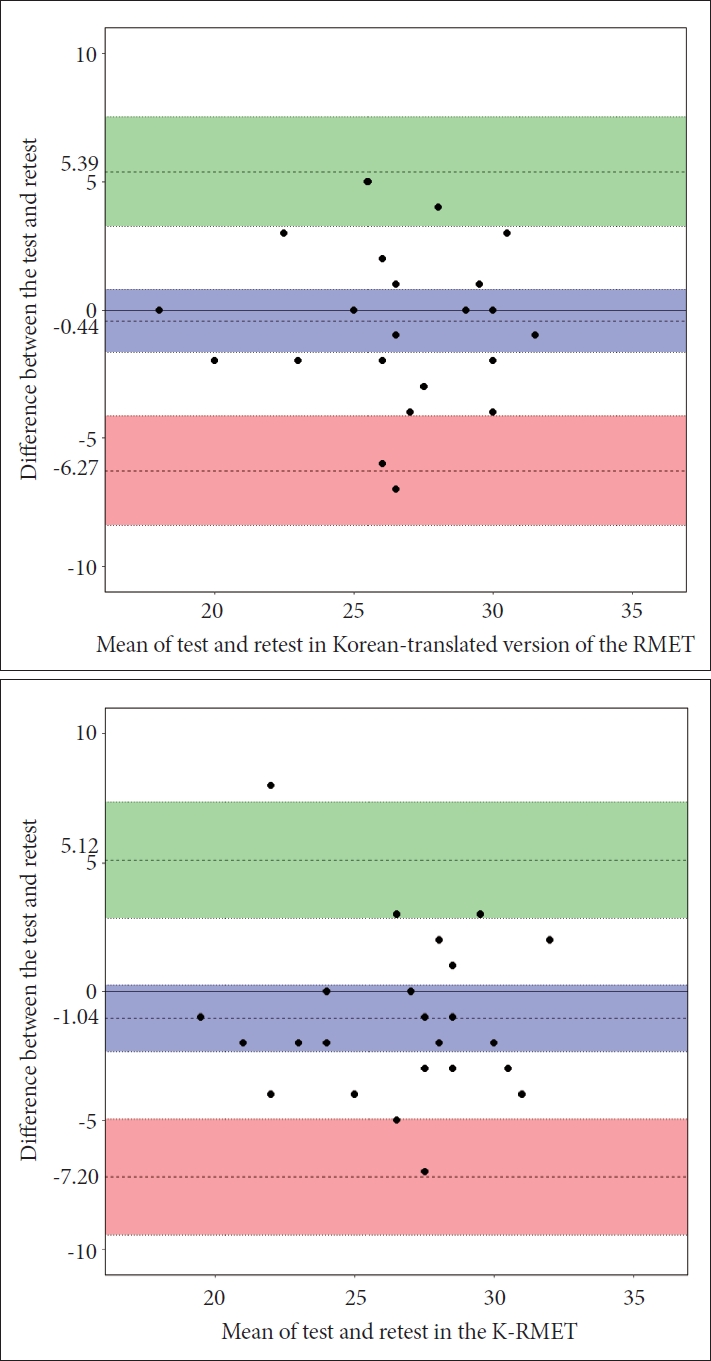
The Bland-Altman plots of the Korean-translated version of the RMET (top) and the K-RMET (bottom) assessments. Mean differences with 95% confidence interval (cobalt blue), upper limit of agreement with 95% confidence interval (vine green), and lower limit of agreement with 95% confidence interval (coral) are displayed. RMET: The Reading the Mind in the Eyes Test.
Confirmatory factor analysis
In the full-scale single-factor, CMIN/df, RMSEA, and SRMR indicated satisfactory fit for both the Korean-translated version of the RMET [χ2 (594)=738.24; p<0.001; CMIN/df=1.24; RMSEA=0.035; 90% CI: 0.026–0.043; SRMR=0.071] and the K-RMET [χ2 (594)=694.63; p=0.003; CMIN/df=1.17; RMSEA=0.029; 90% CI=0.018–0.038; SRMR=0.067], but CFI and TLI were not good for both the Korean-translated version of the RMET (CFI=0.435; TLI=0.400) and the K-RMET (CFI=0.532; TLI=0.504). In the emotional valence 3-factor model proposed by Harkness et al. [35], CMIN/df, RMSEA, and SRMR indicated excellent fit in both the Korean-translated version of the RMET [χ2 (591)=710.72; p<0.001; CMIN/df=1.20; RMSEA=0.032; 90% CI: 0.022–0.041; SRMR=0.070] and the K-RMET [χ2 (591)=686.47; p=0.004; CMIN/df=1.16; RMSEA=0.029; 90% CI: 0.017–0.038; SRMR=0.067], but CFI and TLI were not good in both the Korean-translated version of the RMET (CFI=0.531; TLI=0.500) and the K-RMET (CFI=0.556; TLI=0.527).
Item analysis
Table 1 showed the participants’ choice of answers in each item on the Korean-translated version of the RMET and KRMET. According to the original developmental process of the RMET, the authors presented two criteria in item selection [10]. The first criteria is that participants should select at least 50% of the target word, and the second criteria is that the rate of selecting the foil word in each item should be less than 25%. In the Korean-translated version of the RMET, on three items (2, 5, and 23), the target word was selected by fewer than 50% of the participants, while on nine items (2, 3, 5, 12, 14, 16, 23, 25, and 27), one of the foils was chosen by more than 25%. In the K-RMET, on five items (2, 3, 10, 14, and 28), the target word was selected by fewer than 50% of the participants, while on 10 items (2, 3, 10, 11, 14, 20, 21, 22, 27, and 28), one of the foils was chosen by more than 25%. Overall, nine items (2, 3, 5, 12, 14, 16, 23, 25, and 27) of the Korean-translated version of the RMET, and 10 items (2, 3, 10, 11, 14, 20, 21, 22, 27, and 28) of the K-RMET had difficulty in discrimination.

Distribution of responses in percentages (N=196)
DISCUSSION
The RMET is one of the well-established tests for measuring ToM, and has been widely used in various countries. To the best of our knowledge, this is the first study to develop eye stimuli of the same gender and mental state as the original paper using Korean photographs, and verify the psychometric properties of the Korean-translated version of the RMET and the K-RMET at the same time. The main findings showed that mean accuracy rates of the Korean-translated version of the RMET and the K-RMET were comparable to those of the previous studies, and test–retest reliability and item analysis of the both types of the RMETs were acceptable.
According to the gender of subjects, the overall mean scores and mean scores of the Korean-translated version of the RMET (overall mean=25.65; SD=3.41; mean male=25.46; SD=3.61; mean female=25.82; SD=3.21) and the K-RMET (overall mean=26.72; SD=3.38; mean male=26.17; SD=3.60; mean female=27.24; SD=3.09) were similar to those reported in the original paper, and were within the range of the mean scores of other RMET validation studies (for details, Supplementary Table 2 in the online-only Data Supplement). With regard to accuracy and gender differences, a statistically significant female advantage was observed in most studies of the RMET, including original papers from Baron-Cohen and colleagues [10,38-40]. In the K-RMET, it was also found that females had significantly higher average scores than males. Some studies demonstrated that females were known to recognize faces faster and more accurately than males [41], and better differentiate subtle emotions [42]. Other studies have attempted to explain that females are better than males in distinguishing positive and negative emotions, due to their “attachment promotion” and “fitness threat” derived from an evolutionary perspective [43]. On the other hand, there was no significant difference in performance between males and females in the Korean-translated version of the RMET, supporting the findings of other studies that report the absence of a female advantage, albeit small in number [21,44]. Taken together, the K-RMET may have the advantage in that it properly reflects that are actually occurring in the research fields, such as gender differences in performance. It is considered that further studies that include various ages and cultures will be needed to reach a firm conclusion on the female advantage.
The internal consistency, measured using Cronbach’s alpha, was found to be relatively not good for the Korean-translated version of the RMET (0.542) and K-RMET (0.540). In addition, internal consistency did not improve by excluding any item to improve alpha value in both the Korean-translated version of the RMET and K-RMET. Similarly, the Cronbach’s alpha values of most previous RMET studies were not good [24,30,45-47], with the exception of a few studies that showed an internal consistency of greater than 0.7 [21,48]. It may be explained that the unacceptable internal consistency reliabilities of various versions of the RMET, including the Korean-translated version of the RMET and K-RMET, may be derived from the characteristics of the samples in each study, or the characteristics of the test itself, such as quality of pictures.
Test–retest reliability, as assessed by the ICC and Bland-Altman plot, were shown to be good with the Korean-translated version of the RMET and K-RMET. The ICCs of both Korean-translated version of the RMET were greater than 0.75, corresponding to “good” intraclass correlation coefficients according to the criteria proposed by Koo and Li [31]. Furthermore, the Bland-Altman approach revealed that all mean differences were within the upper/lower limit of agreement except for one case among the 25 retest participants. These results suggested that learning effect is minimal in both types of the RMETs and the measurement results are stable over time.
A CFA was performed using commonly used model fit indices. In the single-factor model, fit indices such as CMIN/df, RMSEA, and SRMR were good for both the Korean-translated version of the RMET and the K-RMET, but did not meet the appropriate criteria in CFI and TLI. In the emotional valence 3-factor, overall model fit was slightly improved, but some fit indices were still poor. By looking at the results of previous studies, similar to the results of the present study in the single-factor and 3-factor model, the overall fit indices did not meet the above mentioned established criteria [22,44], and even a study in the Korean subjects that reported relatively fair model fit, was not seemed to be good in CFI [49]. For ease of understanding, emotions are generally categorized such as positive, negative, and neutral, but in reality, emotions are made up of more complex and subtle combinations of reactions. In line with Vellante et al. [24], proposed that the RMET may also have factor structures of more diverse dimensions rather than a few categories.
For item analysis, among 36 items, nine items of the Korean-translated version of the RMET and 10 items of the K-RMET had difficulty in discrimination. In previous studies [21,24,29,30,44,47,50], questionable items in discrimination (e.g., target response rate) were less than 50% (criteria A), or the foils were selected by more than 25% (criteria B) [10], ranging from 3 to 15 out of 36 items (for details, Supplementary Table 3 in the online-only Data Supplement). Meanwhile, some studies reported a version in which several items were deleted because they did not meet their standards in the development process of the RMET [22,28]. In addition, some items that recorded the target word as foils are diversely distributed. Moreover, in most studies, items 7, 17, and 23 did not meet criteria A or B; whereas the Korean-translated version of the RMET met the criteria for all two items except item 23, and the K-RMET met the criteria for all three items. By analyzing the foil patterns based on emotional valence, as proposed by Harkness et al. [35], the negative valences “doubtful” (item 17) and “defiant” (item 23) were frequently responded with the foils “affectionate” and “curious,” respectively. Furthermore there were differences between the target emotional valence (negative) and the foil (positive or neutral). Similarly, the neutral valence “uneasy” (item 7) was responded with the foil “friendly” in most studies conducted in other countries, and there also was a difference between the target emotional valence (neutral) and the foil (positive). Conversely, for items 2 and 14, unlike previous studies, our study did not meet criteria A or B. However, participants responded to “upset” (item 3) and “accusing” (item 14) with “annoyed” and “arrogant” in the Korean-translated version of the RMET and the K-RMET, respectively, and “irritated” in both. Moreover, there was no difference in the type of the emotional valence between the target and the foil (both are negative).
There have been few studies in which East Asian eye stimuli have been used [25,51]. Moreover, no item analysis on the subject matter has ever been conducted. Thus, there is a limit to direct comparison with our findings. Although it is difficult to conclude that the aforementioned foil patterns are characteristic response patterns of East Asians, some items of the Korean-translated version of the RMET and the K-RMET showed relatively consistent response patterns, which were distinguished from studies conducted in other cultures, follow-up studies to compare emotional response patterns according to culture and race are considered necessary. In addition, since the response patterns are different for each study, it can be considered preferable to use a full version of the test rather than removing specific items, especially for cross-cultural comparison.
The present study had certain limitations. First, for the eye stimuli of the K-RMET, referring to the process of developing emotional stimuli in the original author and other studies, web searching was performed to obtain vivid and natural Korean facial emotional stimuli, which are not artificially made in a laboratory environment. Although only photographs around the eyes of the entire face were used for the development of the test, some of the stimuli were extracted from photos of Korean celebrities. Participants who have identified of the person in the eye stimulus may interpret the intention of the facial expression more positively or negatively based on their familiarity with the person. Second, our study generalized the present findings to all adult ages, since late adolescents to early adults were recruited as participants in the present study, and middle-aged or older adults did not participate. In a group that has a hierarchical culture according to age, such as in Korea, the difference between the age of the person in the eye photo and the age of the participant can affect the participant’s perception of the expression of the eyes in the task. In future studies, empirical works reflecting the above-mentioned relative age differences can be investigated for more accurate measurement. Lastly, in the current study, only CFA for the single-factor assumed in the original paper and the 3-factor widely used in the previous studies were performed. By looking at the results of previous studies, there are studies reported on abbreviated items to maximize model fit [22,44]. However, only different combinations of items are presented for each study, and no consensus result has been reported yet. In order to obtain more robust evidence on the validity of the test, follow-up studies related to the number of factors and the total number of questions will be needed.
In summary, since the RMET is easy to use and can be evaluated in a short time, it has been developed and used in various countries. We developed the RMET, as translated into Korean and the K-RMET by using Korean eye stimuli, resulting to acceptable psychometric properties, such as reliability and item analysis. Future studies should provide additional evidence for convergent and divergent validity through other ToM tests, neurocognitive ability, and personality traits known to be related to social cognition. In addition, it is necessary to expand this study to other clinical populations, such as those with autism spectrum disorder, schizophrenia, and ultra-high risk for psychosis, as well as the general population of various ages and education levels in Korea.
Supplementary Materials
The online-only Data Supplement is available with this article at https://doi.org/10.30773/pi.2020.0289.
Acknowledgements
This work was supported by the Basic Science Research Program through the National Research Foundation of Korea (NRF) funded by the Ministry of Science, ICT & Future Planning, Republic of Korea (grant number 2017R1A2B3008214).
Notes
The authors have no potential conflicts of interest to disclose.
Author Contributions
Conceptualization: Suk Kyoon An. Data curation: Ye Jin Kim, Eunchong Seo, Hye Yoon Park. Formal analysis: Se Jun Koo, Eunchong Seo, Hye Yoon Park. Investigation: all authors. Methodology: Se Jun Koo. Project administration: Suk Kyoon An, Eun Lee. Resources: Ye Jin Kim, Jung Hwa Han. Software: Se Jun Koo. Supervision: Suk Kyoon An. Validation: Jung Hwa Han, Ye Jin Kim, Minji Bang, Jin Young Park. Visualization: Se Jun Koo. Writing—original draft: Se Jun Koo. Writing—review & editing: all authors.